0x00. 概述 前些日子和同事讨论过一个有关Python中共享内存的问题,在这里稍作整理记录一下。
0x01. 什么是共享内存 共享内存指的是一块可以供多个进程访问的内存区域,该物理区域映射到不同进程的地址空间中,在访问该区域的数据时,无需进行额外的数据拷贝,因此对于跨进程交换数据而言,是一种最快的方式。同时,共享内存本身是不具有同步约束的,因此在使用共享内存时一定要自行控制好访问的同步问题。一般常用的方法是使用信号量来控制共享内存的同步。
在Linux系统中,通常共享内存区域的大小被限制在32MB以内。
共享内存有几种不同的方式,比较常用的有传统的SYS V的共享内存和基于mmap文件映射实现的共享内存。
在Linux环境中我们可以通过ipcs命令看到系统中的共享内存情况。
0x02. 一个Python共享内存的例子 shared_memory模块是Python3.8版本中新提供的一个模块。可以方便的使用和管理共享内存。该模块中的共享内存使用的是System V类型。
首先我们先看一个简短的例子。
main.py
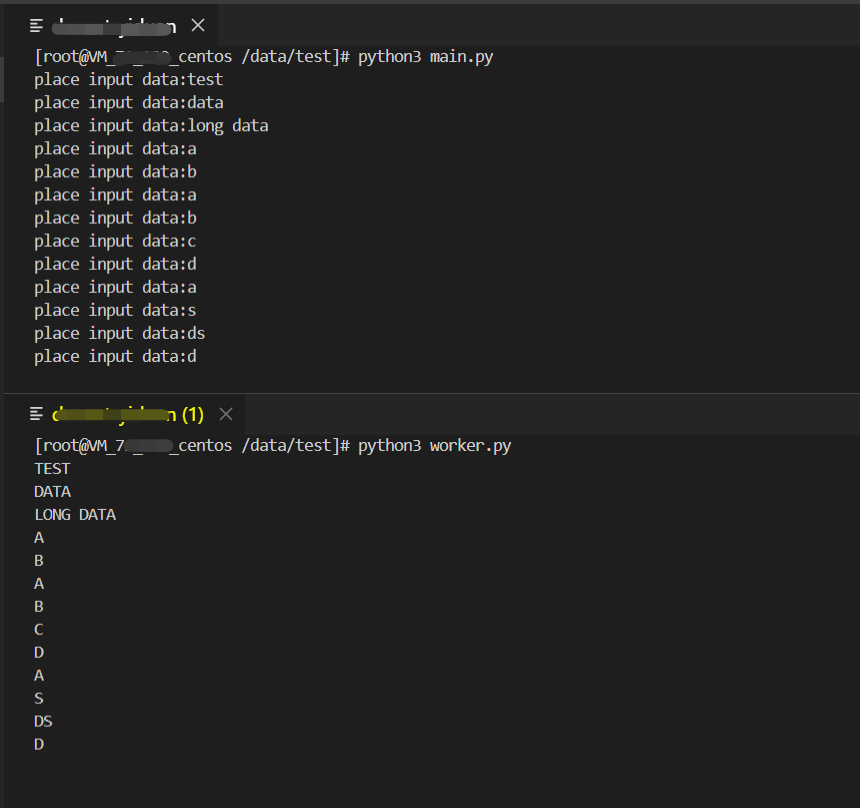
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 from multiprocessing import shared_memoryfrom struct import Struct, pack_intoSHM_KEY = 'PY_SHM_EXAMPLE' class ShmExampleMainAPP : def __init__ (self ): self.shm = shared_memory.SharedMemory(SHM_KEY, True , 8 + 2048 ) self.buffer = self.shm.buf pack_into('I' , self.buffer, 0 , 0 ) self.struct = Struct('II2048s' ) self.round_counter = 0 def handle_input (self ): data = input ("place input data:" ) encode_data = data.encode('utf8' ) data_length = len (encode_data) self.struct.pack_into(self.buffer, 0 , self.round_counter + 1 , data_length, encode_data) self.round_counter += 1 def run (self ): while True : try : self.handle_input() except KeyboardInterrupt: break self.shm.close() self.shm.unlink() if __name__ == '__main__' : app = ShmExampleMainAPP() app.run()
worker.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 from multiprocessing import shared_memoryfrom struct import Structfrom time import sleepSHM_KEY = 'PY_SHM_EXAMPLE' class ShmExampleWorkerAPP : def __init__ (self ): self.shm = shared_memory.SharedMemory(SHM_KEY, False , 8 + 2048 ) self.buffer = self.shm.buf self.struct = Struct('II2048s' ) self.round_counter = 0 def __del__ (self ): self.shm.close() def run (self ): while True : r, s, data = self.struct.unpack_from(self.buffer) data = data[:s] if r != self.round_counter: print (data.decode('utf8' ).upper()) self.round_counter = r sleep(0.5 ) if __name__ == '__main__' : app = ShmExampleWorkerAPP() app.run()
在这个例子中,用主进程创建了一个8+2048B的空间并且接受用户输入,并且每次将当前的计数器和输入的字符长度作为元信息写在前8个字节中,用户输入的字符串则通过UTF8编码后写在后面的空间中。
在子进程中,我们则是读取共享内存区域并且将用户输入转换成大写后输出。
0x03. multiprocessing.shared_memory模块 在shared_memory模块中,主要有两个类可供使用:
SharedMemory: 用于创建或挂载一块已经存在的共享内存块。
ShareableList: 一个元素都存储在共享内存中的类列表对象。
除此之外,在multiprocessing.managers模块中也提供了一个管理类:
SharedMemoryManager: 用于跨进程管理共享内存块。
接下来逐一介绍一下:
SharedMemory 最基本的共享内存类,用于创建或者挂载共享内存块,每个共享内存块都有一个唯一的name标识。当一个进程创建了一个共享内存块后,其他进程就可以通过这个块的名称来挂载这个内存块。
对于一个共享内存块来说,由于它是进程间共享的资源,当一个进程不再使用这个内存块时,其他的进程有可能仍要使用这个内存块。因此在使用共享内存时,要格外注意它的生命周期管理。避免造成内存泄露。
当一个进程不再使用共享内存时,则需要调用close方法来停止该进程对这一块内存的访问。其底层实现本质是释放进程中的buf对象(即memoryview的一个实例)并且关闭mmap。调用close不会真的销毁这块内存区域。当全部进程都不再使用该共享内存块时,则需要调用unlink方法来请求销毁相应的内存区域。需要注意的是,unlink应当且只能被调用一次。
SharedMemory对象主要的使用方法是提供共享内存区域的memoryview供用户使用,即该对象的buf成员。可以通过struct模块进行操作,也可以作为numpy或者PIL的底层buffer出现直接进行操作。
ShareableList 基于SharedMemory实现的类列表对象,本质就是为了方便用户通过内存来共享最基本的数据类型而存在的。这个列表中的元素支持int、float、bool、None和单个大小不超过10MB的字符串/字节数组。ShareableList对象通过一个初始序列创建,创建后则不能像内建的list对象一样进行append、insert等操作,也不能通过切片生成新的ShareableList对象。
从根本来讲,其实ShareableList就是根据初始传入的序列来为初始序列的每个元素预留了相应的内存空间并整体申请了一整块内存区域。可以对其中的元素进行修改,但是修改的限制是不能超过初始化时该位置元素的大小。
由此,可以简化一下上面的例子:
main.py
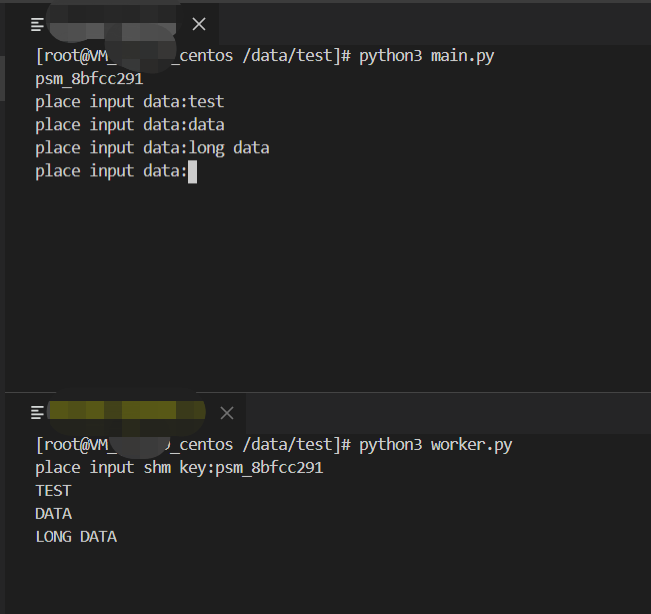
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 from multiprocessing import shared_memorySHM_KEY = 'PY_SHM_EXAMPLE' class ShmExampleMainAPP : def __init__ (self ): self.shl = shared_memory.ShareableList([0 , '' ], name=SHM_KEY) self.round_counter = 0 print (self.shl.shm.name) def handle_input (self ): data = input ("place input data:" ) self.shl[0 ] = self.round_counter + 1 self.shl[1 ] = data self.round_counter += 1 def run (self ): while True : try : self.handle_input() except KeyboardInterrupt: break self.shl.shm.close() self.shl.shm.unlink() if __name__ == '__main__' : app = ShmExampleMainAPP() app.run()
worker.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 from multiprocessing import shared_memoryfrom time import sleepSHM_KEY = 'PY_SHM_EXAMPLE' class ShmExampleWorkerAPP : def __init__ (self ): self.shl = shared_memory.ShareableList(None , name=SHM_KEY) self.round_counter = 0 def __del__ (self ): self.shl.shm.close() def run (self ): while True : r, data = self.shl[0 ], self.shl[1 ] if r != self.round_counter: print (data.upper()) self.round_counter = r sleep(0.5 ) if __name__ == '__main__' : app = ShmExampleWorkerAPP() app.run()
在这个优化后的例子中,由于使用了ShareableList对象,当内部存储字符串时,它管理了字符串的长度等信息,因此用户也就无需在元信息中保存数据的长度信息了。
SharedMemoryManager 与multiprocessing.Manager类似,都是一个独立的进程对象,SharedMemoryManager(下面简称为SMM)类在用户调用了其实例的start方法后,会启动一个独立的进程用来响应用户的创建共享内存请求,并且管理其创建的共享内存的整个生命周期。
SMM对象作为一个高级API可以极大的降低使用共享内存的难度,可以不用去刻意关注所使用的共享内存区域的释放。使用完毕之后调用SMM对象的shutdown方法即可非常方便的关闭其创建的全部共享内存。
不过作为SMM对象,使用方便的代价是它会作为一个独立进程存在,对于很多使用场景来说,有一些过于“重”了。
SMM对象提供了两个方法,SharedMemory和ShareableList,用来创建相应的对象。
对刚才的例子稍作修饰:
main.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 from multiprocessing import managersclass ShmExampleMainAPP : def __init__ (self ): self.smm = managers.SharedMemoryManager() self.smm.start() self.shl = self.smm.ShareableList([0 , '' ]) self.round_counter = 0 print (self.shl.shm.name) def handle_input (self ): data = input ("place input data:" ) self.shl[0 ] = self.round_counter + 1 self.shl[1 ] = data self.round_counter += 1 def run (self ): while True : try : self.handle_input() except KeyboardInterrupt: break self.smm.shutdown() if __name__ == '__main__' : app = ShmExampleMainAPP() app.run()
worker.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 from multiprocessing import shared_memoryfrom time import sleepclass ShmExampleWorkerAPP : def __init__ (self, name ): self.shl = shared_memory.ShareableList(None , name=name) self.round_counter = 0 def __del__ (self ): self.shl.shm.close() def run (self ): while True : r, data = self.shl[0 ], self.shl[1 ] if r != self.round_counter: print (data.upper()) self.round_counter = r sleep(0.5 ) if __name__ == '__main__' : shm_key = input ('place input shm key:' ) app = ShmExampleWorkerAPP(shm_key) app.run()
在这个例子中,各种操作都比一开始的例子简单了很多。不过由于SHM的实现机制,不能再使用事先约定好SHM_KEY的方式在其他进程中挂在相应的共享内存区域了,只能通过其他方式将创建好的共享内存对象的key传递给其他的进程。
0x04. 几个典型的使用场景 通过上面的例子不难发现,共享内存虽然是非常高效的跨进程通信方案,但是同样使用复杂度也是最高的,需要用户自行控制进程间的同步问题。对于Python应用而言在很多场景下这种复杂度换回的效率提升其实是得不偿失的。
那么一般需要在什么场景下使用这种方式来进行跨进程通信呢?
共用数据集
共用数据集是最常见的使用场景之一了。例如在做AI训练时,可以将数据集加载在共享内存区域中同时提供给多个进程进行训练。由于训练进程对于数据集本身都只有读操作,因此也不用担心进程同步和读写冲突的问题了。这个场景下可以极大的节约内存空间并且减少主进程到训练进程间的数据拷贝,从而提升整体的资源利用效率。
与不同语言实现的需要大量数据通信的程序间进行交互
一个最典型的例子是在音视频领域,可以将Python程序实时生成的图像数据通过共享内存的方式输出给ffmpeg进行实时的编码和串流操作。同样,反向的操作也是可行的,通过ffmpeg捕获视屏数据解码后通过共享内存的方式输出到我们的Python分析程序中对画面元素进行分析。
作为信号之外的另一种通知方式
线上程序对配置的热加载,我们通常是通过发送信号来通知进程去进行配置更新的,但是除了发送信号之外,修改共享内存同样是一种可行的处理方案。我们可以让线上程序去监听某一个共享内存的区域,与此同时,我们在需要热更新配置时,只需要通过外围脚本将新的配置写到共享内存区域并且修改相应的标志位,线上程序即可通过一次内存拷贝将新的配置读取到自己的私有内存空间中了。
当然还有一些其他场景适合使用共享内存进行进程间的通信和数据同步,在这里就不一一列举了。