双十一又要来了,为剁手党萌做了一点微小的事情
- 涉及最简单的页面分析
- 简单的多进程编程
转眼又到了双十一,分享一个之前爬京东商品评论的爬虫,为剁手党萌提供一些微小的帮助。
每每想到要在网上购买商品,第一个想到的就是要去看看买家们怎么说,但是难以避免的,在页面上一次只能看到10条评论,频繁的翻页操作真的是好麻烦。再者有时候对于(没钱的我)[划掉]选择困难症患者来说总有这么一个闹心事,比如我想买一部手机,我同时看好水果牌的某一款,我也看好大菊花的某两款,我还看好大法的某一款,那么当我逐一看某一款的评论时,都会给我一个感觉“哇,好棒,买买买。”相反在现实里,小伙伴们一起讨论的话就会是另外一番场景了:A:“水果好看。”B:“支持国产。”C:“坚定信仰。”A:“水果做工好。”B:“我用麒麟。”C:“坚定信仰。”通过这样的交替看评论,反而能使人更客观一点。但是我们在一个京东的页面里面显然是不可能看见友商竞品的评论了。我们总不能开好几个标签手动看吧。鉴于此,这点小事是难不倒程序猿的。写个爬虫存起来,想怎么看就怎么看(:зゝ∠)
说干就干,必然还是人生苦短我用python。
第一步必然是分析页面,随时打开一个评论页面,比如以http://item.jd.com/3717578.html这个地址为例。在第一条评论的位置右键审查元素,可以看到这样的信息:

发现很明显,所有的评论内容都是在一个类为p-comment的div中。随手在下面的console中敲一下$('.p-comment')一看返回结果刚好是10条评论的数组。一看到这个,不由的让人想到,这下好办了pyquery几乎可以不费什么功夫就把所有的内容抓到了。
但是根据我的经验,这样的页面一般评论都是异步加载的,可能会有更简单的办法来处理这件事情。比如挖掘一下有没有评论接口什么的。戳回商品信息页面,在Chrome的Developer Tools的Network标签里禁用缓存,刷新页面然后戳一下商品评论,发现又发起了81个请求,那么很有可能评论就藏在这里面。在filter中选择XHR发现居然是空的,那么评论没有直接使用json传回来,一定被藏起来了。这样真的是有点不太友好哇(:зゝ∠)
不过这样的事情难不倒段喵喵,把filter切到js看看这些请求回来的js有没有什么异常。为嘛会想到js呢。对于这个问题可以去查一下JSON到底是什么。往下翻几个就看到了一个请求名字是productPageComments.action戳开一看果然是一个函数调用包着一个大的json。那么我们要找的json就在这里了,可是还得处理一下外面这一层。看起来似乎不太好办,但是再回头看一眼这个请求本身最后带着一个查询参数是callback=fetchJSON_comment98vv2125发现和respose中包着这个json的函数调用名字一样。这样的话,如果我们把这个参数去掉发一个请求试试。
一个完整的JSON文件get√,看看上面的查询参数,我们只要修改对于的productId就可以得到不同商品的评论了,当然还有page和pageSize参数。分别是评论的第几页和每页的评论数。但是不知道为嘛这个pageSize参数是个咸鱼,不管你填多少都只能拿到10条评论。
接下来的事情简单了,分析一下json文件,先格式化了,然后简单折叠一下。就可以看到这样的结构了:
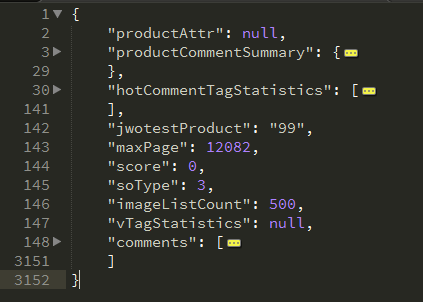
productCommentSummary是产品评论总结,里面有一些好评率,评论总数之类的东西,hotCommentTagStatistics标签信息,maxPage最大页码数,comments评论列表。
剩下的内容就无比简单了,urllib2和json两个包的使用,为了效率高可以用multiprocessing多进程处理,为了容错和高效维护数据,内容直接写入MySQL就OK了。
多的不用说了,直接上代码了w
1 | import urllib2 |
代码放在GITHUB上,如果你觉得不错的话,欢迎点赞投喂w
